
La simple observación de las búsquedas en Google Trends de las palabras clave «Inteligencia Artificial», en Argentina y Globalmente, confirma que está muy presente en muchas conversaciones diarias. El siguiente gráfico muestra la proporción de búsquedas:
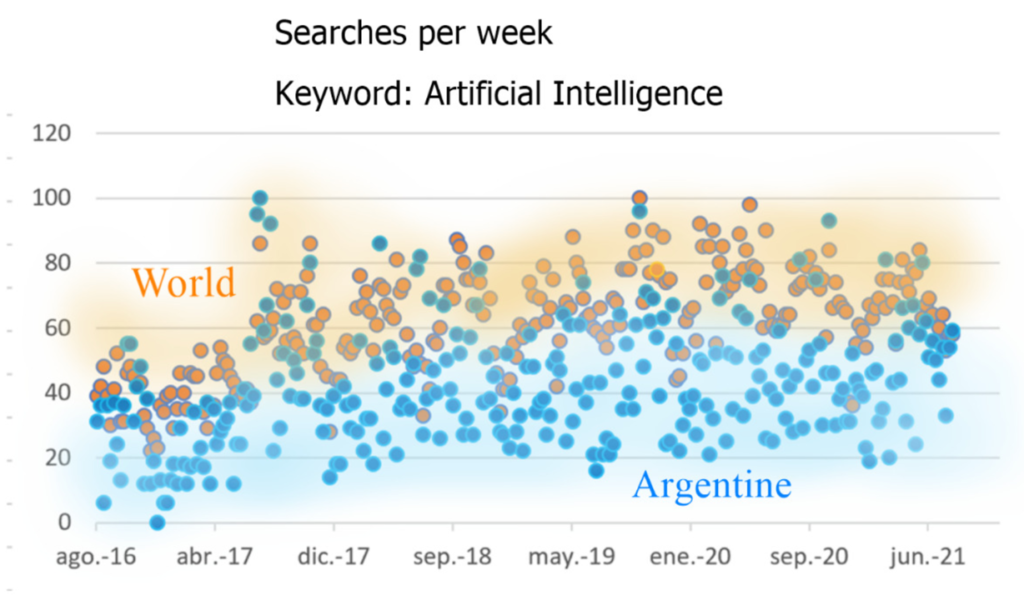
En particular, el mundo (amarillo) tiene sistemáticamente más búsquedas de estas palabras que Argentina (azul). Esto se vuelve más pronunciado cuando buscamos las palabras «aprendizaje automático», que generalmente recibe poderes casi mágicos en relación con su capacidad para resolver problemas comerciales.
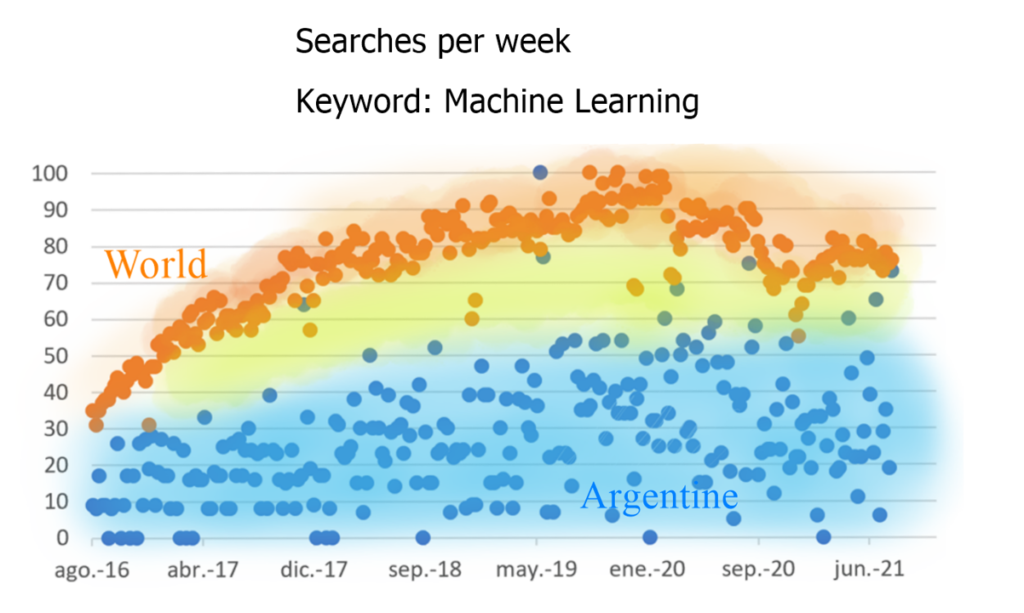
La marcada diferencia (banda amarilla que separa la proporción de búsquedas en Argentina y el resto del mundo) vuelve a llamar la atención. Un valor de 100 indica la máxima popularidad de un término, mientras que 50 y 0 indican que un término es la mitad de popular o nada.
La Inteligencia Artificial (IA) intenta hacer que las máquinas imiten al hombre e incluye el concepto de Machine Learning (ML) como dimensión clave. Específicamente, es importante comprender qué garantiza y qué no garantiza el ML cuando se utiliza para resolver problemas comerciales. Hay 4 enfoques clásicos para definir la IA: una máquina puede actuar y pensar humana y racionalmente.
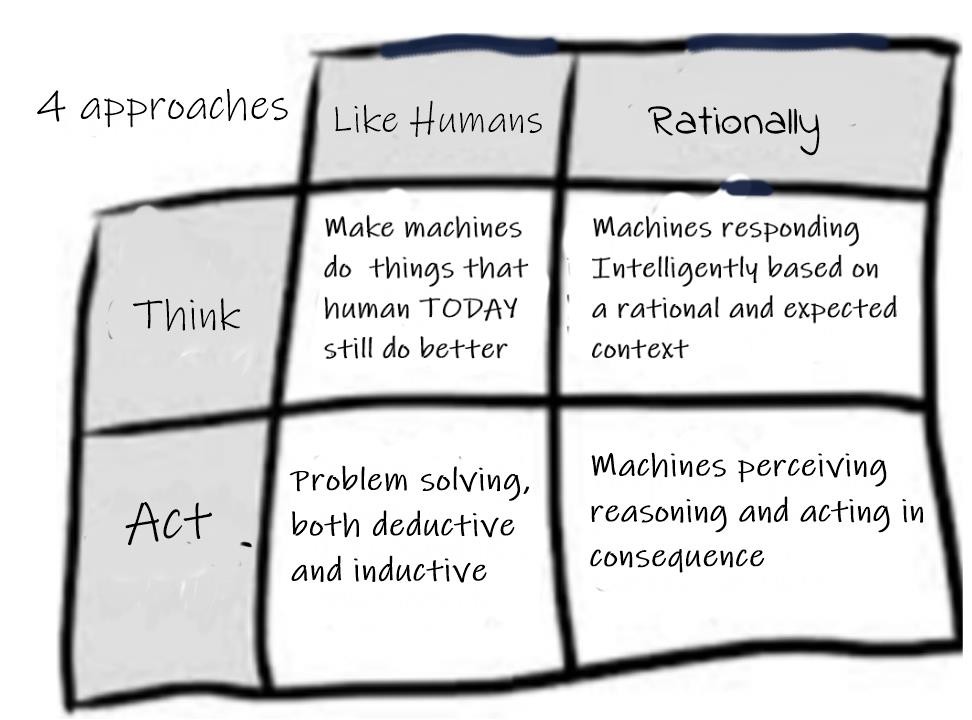
Una de las capacidades básicas requeridas de esta máquina, en cuanto a actuar y pensar, es aprender (Aprender). Entonces, para que la máquina intente imitar al hombre, primero debe interactuar con el entorno y desde él detectar y extrapolar patrones de datos que se están recibiendo. De ahí el término aprendizaje automático.
¿Qué significa aprender en estos términos? Cada aspecto observable de la realidad es generado por una serie de causas instantáneas o retardadas, que se acumulan y expanden por umbrales en un número infinito de formas impactantes. Los datos observables cambian de estado cuando todos o algunos de ellos inducen movimiento. Si pudiéramos entender el qué, cuándo, cómo y por qué cambian los aspectos interesantes de la realidad, claramente tendríamos la capacidad de influir en los eventos a su antojo y conveniencia.
En términos matemáticos esto significa que toda la órbita de las variables explicativas que son causas de un evento observable, al que llamaremos objetivo, están relacionadas con él a través de una función desconocida.
Machine Learning, en el caso supervisado, solo intenta encontrar esa función con las variables que se ofrecen, dando tres situaciones muy comunes.
1 – Datos basura
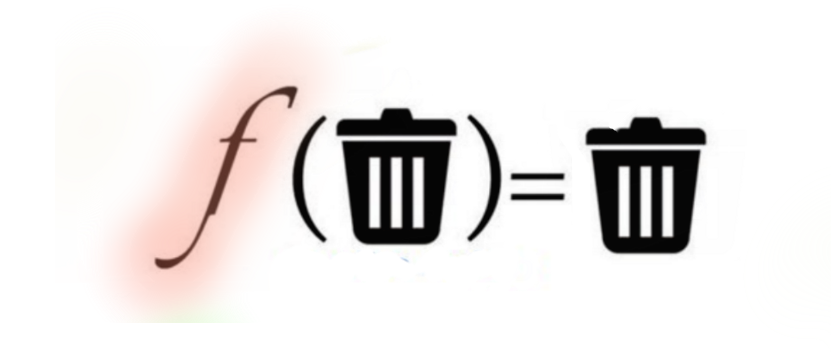
Si los datos son ‘basura’, la salida es ‘basura’, incluso si usa el algoritmo más complejo y poderoso disponible. El aprendizaje automático no puede aprender nada en este caso.
2 – Objetivo especificado totalmente
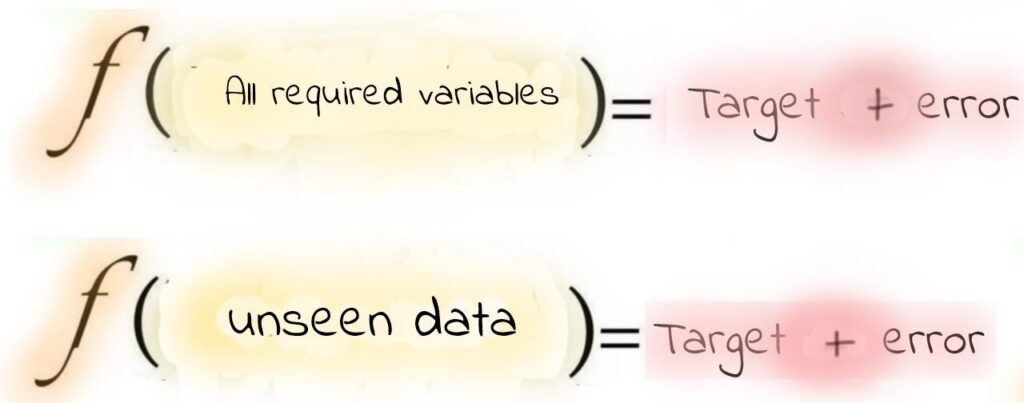
Si el objetivo está completamente especificado (se incluyen todas las variables explicativas), el aprendizaje automático podría aprender el objetivo con un error mínimo, a pesar de la enorme complejidad que podría implicar.
3 – Objetivo no especificado totalmente
Esta es la situación más común que se traduce en que solo se pueden especificar algunas variables relevantes, proxies de las necesarias, u otras variables que son redundantes por alta interacción con otras que no tienen una relación clara con el target.
El aprendizaje automático solo garantiza eliminar el sesgo y minimizar el error. Lo que a menudo se confunde es lo último. Este error se refiere al error teórico que se puede lograr cuando las variables ofrecidas al algoritmo intentan aprender el objetivo. Este error teórico mínimo no depende del Machine Learning (solo depende de las variables). ML solo garantiza llevarlo a su valor mínimo mientras intenta alcanzar el teórico, que aún puede ser inaceptable. El sesgo representa la capacidad de memoria que tenía la función cuando fue entrenada. Memorizar implica aprender detalles no generalizables y se produce el famoso sobreentrenamiento o ‘sobreajuste’ y, por tanto, el aprendizaje automático falla.
En resumen, el Machine Learning solo garantiza que dado un conjunto de variables explicativas y un target asociado, intentará aprender este último con el mínimo de error y generalizar ese aprendizaje específico a cualquier dato futuro que se le presente. No promete que el objetivo se aprenda perfectamente, a pesar del uso de modelos altamente complejos. Solo aprenderá (mucho, medio o poco) lo que permiten las variables incluidas pudiendo así generalizar a datos futurosNo hace magia ni encuentra patrones que no existen en los datos para explicarle al objetivo.
El aprendizaje automático es un proceso laborioso e interdisciplinario. Si resolvió un problema simplemente proporcionando un conjunto de datos y ejecutando un algoritmo, el problema era trivial. En general, este no es el caso.
